Dưới đây là 7 xu hướng khoa học dữ liệu phát triển nhanh nhất cho năm 2022 và xa hơn nữa.
Sự Bùng Nổ Trong Video Và Âm Thanh Deepfake
Deepfakes sử dụng trí thông minh nhân tạo để thao túng hoặc tạo nội dung đại diện cho người khác. Thường thì đây là hình ảnh hoặc video của một người được sửa đổi để giống người khác. Nhưng nó cũng có thể là âm thanh. Quay trở lại năm 2019, một công ty AI đã đánh giá sâu giọng nói của podcaster nổi tiếng Joe Rogan đến mức nó ngay lập tức lan truyền trên mạng xã hội. Và công nghệ chỉ được cải thiện kể từ đó.
Có rất nhiều phạm vi cho phép sử dụng công nghệ này với mục đích xấu. Một giọng nói giả trầm khác đã được sử dụng để lừa đảo một công ty năng lượng có trụ sở tại Vương quốc Anh với số tiền € 220.000. Trên thực tế, ngày càng có nhiều người quan tâm đến phương thức tìm kiếm được gọi là "lừa đảo bằng giọng nói". Mà về cơ bản là thuật ngữ "chính thức" cho việc thực hành.
Các Ứng Dụng Khác Được Tạo Bằng Python
Python là ngôn ngữ lập trình dùng để phân tích dữ liệu. Bởi vì Python có một số lượng lớn các thư viện khoa học dữ liệu miễn phí như Pandas và các thư viện học máy như Scikit-learning. Nó thậm chí có thể được sử dụng để phát triển các ứng dụng blockchain. Thêm vào đường cong học tập thân thiện này cho người mới bắt đầu và bạn có một công thức để thành công.
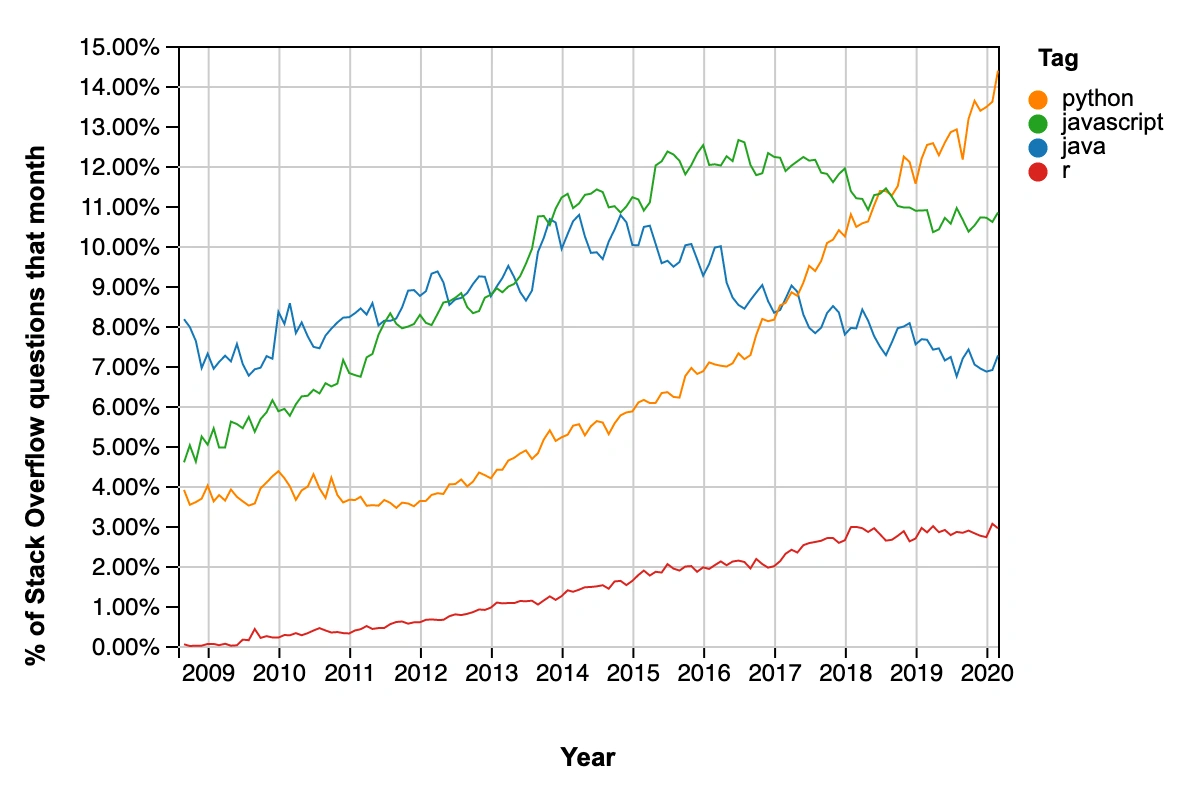
Python hiện có số lượng câu hỏi Stack Overflow cao nhất mỗi tháng
Python hiện được xếp hạng là ngôn ngữ phổ biến thứ 3 nói chung bởi công ty phân tích RedMonk. Và xu hướng tăng trưởng phổ biến cho thấy nó đang trên đà trở thành số 1 trong vòng ba năm tới.
Gia Tăng Nhu Cầu Về Các Giải Pháp AI Từ Đầu Đến Cuối
Công ty Enterprise AI Dataiku hiện trị giá 4,6 tỷ đô la ( theo TechCrunch ) sau khi Google mua cổ phần của công ty vào tháng 12 năm 2019. Công ty khởi nghiệp AI giúp khách hàng doanh nghiệp làm sạch các tập dữ liệu lớn của họ và xây dựng các mô hình học máy. Bằng cách này, các công ty như General Electric và Unilever có thể có được những hiểu biết sâu sắc, có giá trị từ lượng dữ liệu khổng lồ của họ. Và tự động hóa các tác vụ quản lý dữ liệu quan trọng. Trước đây, các doanh nghiệp sẽ phải tìm kiếm chuyên gia trong tất cả các phần khác nhau của quy trình và tự ghép chúng lại với nhau. Nhưng Dataiku xử lý toàn bộ chu trình khoa học dữ liệu từ đầu đến cuối với một sản phẩm duy nhất. Và bởi vì điều này, họ nổi bật. Các doanh nghiệp muốn có các giải pháp khoa học dữ liệu end-to-end. Và các công ty khởi nghiệp cung cấp thứ này sẽ ăn cả thị trường.
Các Công Ty Thuê Nhiều Nhà Phân Tích Dữ Liệu Hơn
Các lượt tìm kiếm "nhà phân tích dữ liệu" đã tăng 93% kể từ năm 2017. Sự quan tâm đến vai trò của khoa học dữ liệu này cho thấy sự tăng trưởng của gậy khúc côn cầu. Nhu cầu về các nhà phân tích dữ liệu đã tăng vọt trong vài năm qua. Và, phần lớn nhờ vào dữ liệu đến từ Internet of Things (IoT) và những tiến bộ trong điện toán đám mây, lưu trữ dữ liệu toàn cầu được thiết lập để tăng từ 45 zettabyte lên 175 zettabyte vào năm 2025 . Vì vậy, nhu cầu về các chuyên gia phân tích và phân tích tất cả dữ liệu này được thiết lập để tăng lên.
Có rất nhiều chương trình phân tích dữ liệu có thể sắp xếp tất cả. Và "chuyển đổi kỹ thuật số" được cho là đã thay thế nhiều nhiệm vụ kinh doanh do con người dẫn dắt. Chắc chắn, máy móc có thể giúp phân tích dữ liệu. Nhưng dữ liệu lớn thường cực kỳ lộn xộn và thiếu cấu trúc thích hợp. Đó là lý do tại sao con người cần thiết để xử lý dữ liệu đào tạo theo cách thủ công trước khi nó được các thuật toán học máy nhập vào. Việc mọi người tham gia vào đầu ra cũng ngày càng phổ biến. Kết quả do AI tạo ra không phải lúc nào cũng đáng tin cậy hoặc chính xác, vì vậy các công ty máy học thường sử dụng con người để dọn dẹp dữ liệu cuối cùng. Và viết một bản phân tích về những gì họ tìm thấy theo cách mà các bên liên quan không phải là công nghệ có thể hiểu được.
Khoa học dữ liệu và phương pháp học máy của những năm 2020 sẽ ít nhân tạo và tự động hơn so với dự kiến ban đầu. Trí thông minh tăng cường và trí tuệ nhân tạo trong vòng lặp của con người có thể sẽ trở thành một xu hướng lớn trong khoa học dữ liệu.
Các Nhà Khoa Học Dữ Liệu Tham Gia Kaggle
Tăng trưởng tìm kiếm cho "Kaggle" đã tăng 55% trong 5 năm. Nền tảng khoa học dữ liệu có hơn 5 triệu người dùng trên 194 quốc gia. Kaggle đã nhanh chóng phát triển trở thành cộng đồng khoa học dữ liệu lớn nhất thế giới. Và với hơn 8 triệu người dùng trên 194 quốc gia, nó không hề chậm lại. Nhiều nhà khoa học dữ liệu đang chớm nở hiện bắt đầu với Kaggle để bắt đầu hành trình học máy của họ. Và đăng tiến trình của các dự án máy học của họ trong thời gian thực. Người dùng thậm chí có thể chia sẻ tập dữ liệu và tham gia các cuộc thi để giải quyết các thách thức về khoa học dữ liệu với mạng nơ-ron. Hoặc làm việc với các nhà khoa học dữ liệu khác để xây dựng các mô hình trong bàn làm việc khoa học dữ liệu dựa trên web của Kaggle.
Gia Tăng Sự Quan Tâm Đến Việc Bảo Vệ Dữ Liệu Của Người Tiêu Dùng
"Quyền riêng tư về dữ liệu" đã chứng kiến mức tăng trưởng tìm kiếm là 125% trong 10 năm qua. Mọi người hiện đang tìm kiếm về quyền riêng tư dữ liệu của họ với số lượng lớn hơn theo tháng. Nhận thức của người tiêu dùng về quyền riêng tư dữ liệu đã tăng lên sau vụ bê bối Cambridge Analytica . Trên thực tế, CIGI-Ipsos nhận thấy rằng hơn một nửa số người tiêu dùng trở nên quan tâm hơn đến quyền riêng tư của dữ liệu trong năm sau khi tiết lộ.
Các nền tảng như Facebook và Google, trước đây đã thu thập và chia sẻ dữ liệu người dùng một cách tự do, kể từ đó đã phải đối mặt với phản ứng dữ dội của pháp luật và sự giám sát của công chúng. Xu hướng bảo mật dữ liệu rộng rãi hơn này có nghĩa là các tập dữ liệu lớn sẽ sớm bị ngăn cản và khó có được hơn. Các doanh nghiệp và các nhà khoa học dữ liệu sẽ cần phải điều chỉnh luật pháp, chẳng hạn như Đạo luật về Quyền riêng tư của Người tiêu dùng California , có hiệu lực vào đầu năm 2020. Và điều này có thể trở thành một trở ngại cho khoa học dữ liệu khi nói đến việc thu thập và sử dụng dữ liệu người tiêu dùng trong tương lai.
Các Nhà Phát Triển AI Chống Lại Máy học của Đối Thủ
Các tìm kiếm " máy học đối phương" đã tăng đáng kể trong thập kỷ 99x + qua. Máy học đối phương là nơi kẻ tấn công nhập dữ liệu vào mô hình máy học với mục đích gây ra sai lầm. Về cơ bản là một ảo ảnh quang học được thiết kế cho một chiếc máy. Các nhà khoa học dữ liệu sẽ cần phải bảo vệ dữ liệu trước các đối thủ của mình
Đó là 7 xu hướng khoa học dữ liệu lớn nhất trong vòng 3-4 năm tới. Khoa học dữ liệu, giống như bất kỳ khoa học nào, đang thay đổi từng ngày. Từ quản trị dữ liệu đến công nghệ deepfake, ngành khoa học dữ liệu sẽ có một số thay đổi lớn.
Nguồn: Exploding Topics
Xem nhiều




Bắt đầu dự án của bạnNgay hôm nay!



